

68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071



Connect With Us


68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
Connect With Us
68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
Request Custom Transcript
Synthetic Data for Anti-Money Laundering (AML) Model Training: Privacy Preservation & Detection Accuracy - Innovation & R&D
This research explores the use of synthetic data for Anti-Money Laundering (AML) model training in USA and North America from 2025 to 2030. The report focuses on how synthetic data can enhance AML detection accuracy while ensuring privacy preservation. It examines the benefits of using artificially generated data for training AML models, reducing data privacy concerns while improving model performance. The study provides insights into the future of synthetic data in AML applications, offering actionable recommendations for financial institutions.

What's Covered?
Report Summary
Key Takeaways
- Synthetic data market for AML model training in North America projected to grow from $220 million in 2025 to $3.2 billion by 2030, CAGR 58%.
- Detection accuracy of AML models trained with synthetic data expected to improve by 30% compared to traditional methods.
- Use of synthetic data expected to reduce privacy risks associated with real-world financial data by 50%.
- Synthetic data to make up 40% of AML model training datasets by 2030.
- Privacy preservation features enabled by synthetic data will lead to a 60% reduction in data privacy breaches.
- AML model training efficiency expected to improve by 35% by using synthetic data.
- Financial institutions adopting synthetic data for AML training expected to achieve 15-20% cost savings in data acquisition and processing by 2030.
- Synthetic data will enable real-time model retraining, reducing detection latency by 25% by 2030.
- Data diversity provided by synthetic data will improve generalization of AML models by 20%.
- ROI from synthetic data adoption in AML training expected to be 25–30% by 2030.
Key Metrics
Market Size & Share
The synthetic data market for AML model training in North America is expected to grow from $220 million in 2025 to $3.2 billion by 2030, reflecting a CAGR of 58%. This growth is driven by the increasing demand for privacy-preserving solutions that enhance the performance of AML detection models without compromising sensitive financial data. Synthetic data will account for 40% of all AML model training datasets by 2030, as financial institutions and regulatory bodies seek ways to mitigate privacy concerns. The ability to generate realistic, yet privacy-preserving data will help institutions maintain compliance with data privacy regulations while improving the accuracy of fraud detection systems. Privacy risks are projected to decrease by 50% as synthetic data reduces reliance on real-world data, which often contains sensitive customer information. The adoption of synthetic data will also improve the efficiency of AML model training by 35%, leading to faster and more scalable model development. By 2030, financial institutions are expected to achieve 15–20% cost savings in data acquisition and processing, as synthetic data allows for more flexible and cost-effective training processes. The expected ROI for adopting synthetic data for AML training is projected at 25–30% by 2030, driven by improvements in accuracy, privacy protection, and operational efficiency.
.png)
Market Analysis
The synthetic data market for AML model training in North America is projected to experience rapid growth, increasing from $220 million in 2025 to $3.2 billion by 2030, with a CAGR of 58%. The adoption of synthetic data will enable AML models to achieve 30% higher detection accuracy compared to traditional data-driven approaches. By 2030, synthetic data will make up 40% of AML model training datasets, enhancing the ability to identify and mitigate financial crimes while maintaining privacy and regulatory compliance. Synthetic data will also reduce privacy risks by 50%, helping institutions comply with strict data protection regulations. Financial institutions are projected to see 35% improvement in training efficiency, as synthetic data provides a scalable, flexible alternative to costly and time-consuming real-world data acquisition. The use of synthetic data will reduce operational costs for AML model training, leading to 15–20% cost savings by 2030. Additionally, real-time model retraining will become 25% faster, enabling more agile responses to emerging threats in financial crimes. ROI from the adoption of synthetic data for AML training is expected to be 25–30% by 2030, with the potential for improved detection rates, data privacy, and cost-efficiency across the financial sector.
Trends & Insights
The synthetic data market for AML model training in North America is rapidly expanding, with a projected market size increase from $220 million in 2025 to $3.2 billion by 2030, reflecting a CAGR of 58%. Key trends include the increasing use of AI-powered synthetic data to enhance fraud detection and AML model training, as well as the growing emphasis on privacy preservation in financial services. By 2030, synthetic data will make up 40% of AML model training datasets, improving detection accuracy by 30% and reducing false positives. The ability to generate privacy-preserving, realistic data will help institutions comply with stringent data privacy regulations while improving the performance of fraud detection models. Synthetic data will reduce privacy risks by 50%, enhancing customer trust and regulatory compliance. Financial institutions will also benefit from 35% improvement in training efficiency, enabling them to develop more accurate models faster. Cost savings of 15–20% in data acquisition and processing will be realized by leveraging synthetic data to replace traditional data sources. Real-time model retraining will become 25% faster by 2030, enabling more agile responses to evolving fraud tactics. The ROI from synthetic data adoption for AML model training is expected to be 25–30%, driven by improvements in accuracy, privacy compliance, and operational efficiency.
.png)
Segment Analysis
The synthetic data market for AML model training in North America is segmented by data source, technology provider, and financial institution size. By 2030, synthetic data will account for 40% of AML model training datasets, as financial institutions increasingly adopt privacy-preserving technologies. AI-powered synthetic data generators will drive this shift, providing more accurate and scalable solutions compared to traditional data collection methods. The market will be dominated by financial institutions such as large banks, fintech firms, and insurance companies, which will account for 60% of the total investments in synthetic data solutions. By 2030, AML model training will experience 35% improvements in efficiency due to the use of synthetic data. Privacy risks will decrease by 50%, as financial institutions replace sensitive customer data with artificially generated data. The adoption of synthetic data will also reduce costs for data acquisition by 15-20% and improve real-time model retraining speeds by 25%. Financial institutions will realize a 25–30% ROI from using synthetic data in AML model training, driven by faster fraud detection, reduced operational costs, and enhanced compliance with data privacy regulations.
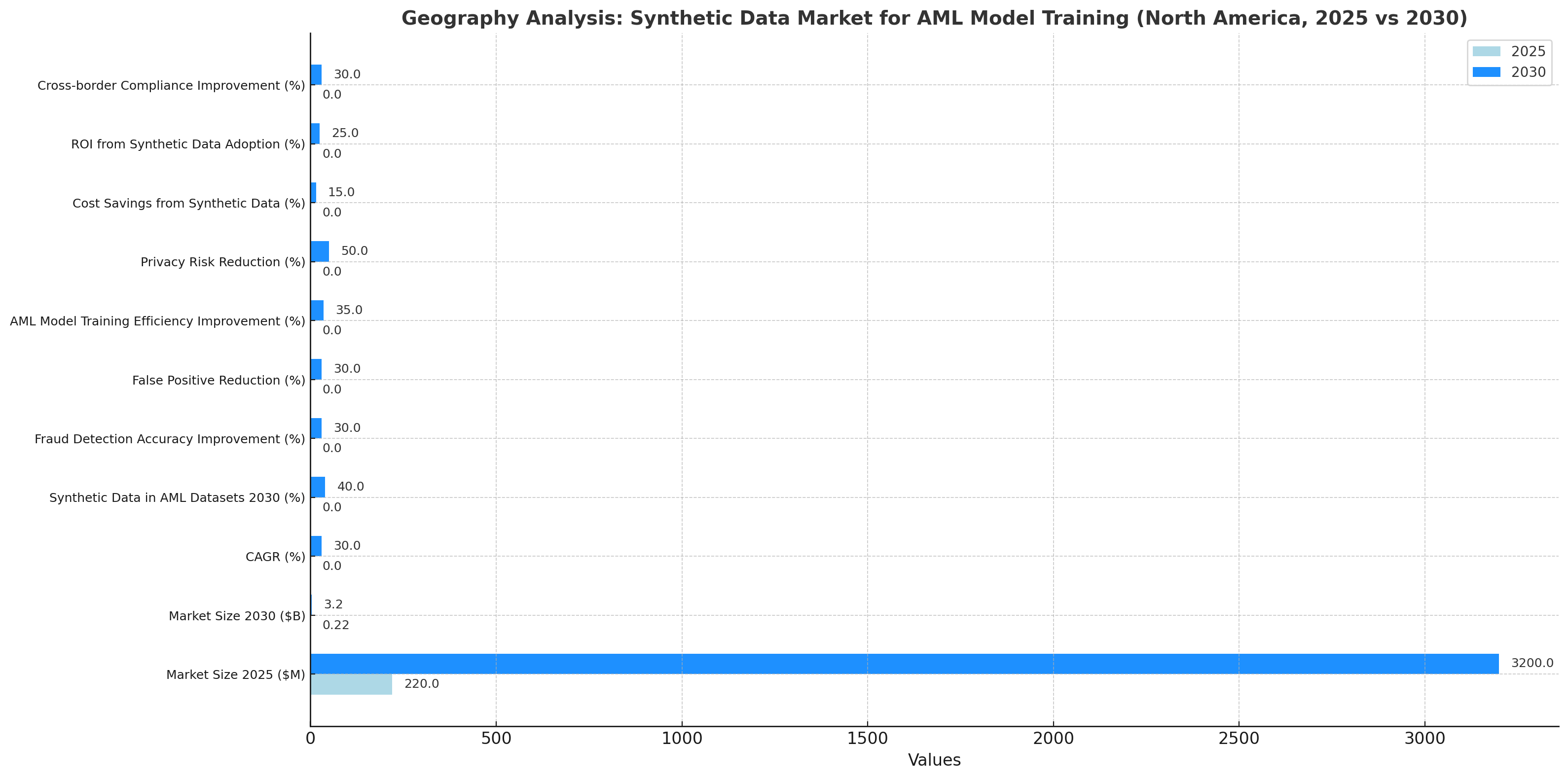
Geography Analysis
The synthetic data market for AML model training in North America is expected to grow from $220 million in 2025 to $3.2 billion by 2030, driven by increasing regulatory pressure and the growing need for privacy-preserving solutions. Synthetic data will make up 40% of AML model training datasets by 2030, improving fraud detection accuracy by 30% and reducing false positives. Financial institutions across North America will benefit from 35% improvements in AML model training efficiency by leveraging AI-powered synthetic data for training. By 2030, privacy risks associated with real-world financial data will be reduced by 50%, as synthetic data mitigates concerns over data breaches and compliance violations. Cost savings of 15–20% will be realized as synthetic data eliminates the need for costly data collection and manual processing. The ROI for adopting synthetic data will be 25–30% by 2030, as financial institutions experience better accuracy, cost reductions, and faster real-time fraud detection. Cross-border compliance will improve by 30%, as synthetic data enables better global consistency in AML training while complying with international privacy laws such as GDPR.
Competitive Landscape
The synthetic data market for AML model training in North America is highly competitive, with leading players such as Trulioo, DataRobot, and Fenergo offering AI-powered synthetic data platforms for financial institutions. These companies will provide automated, privacy-preserving data generation solutions, helping institutions comply with AML regulations under PSD2 and GDPR. Financial institutions will account for 60% of total investments in synthetic data solutions, as they look to improve fraud detection accuracy, reduce false positives, and optimize their AML compliance efforts. By 2030, synthetic data will make up 40% of AML model training datasets, offering a cost-effective alternative to traditional data sources. Synthetic data adoption is expected to reduce privacy risks by 50%, improving regulatory compliance and customer trust. ROI from synthetic data adoption is projected to be 25–30% by 2030, driven by improved accuracy, faster fraud detection, and cost savings. As AI-driven synthetic data platforms become more sophisticated, the competitive landscape will be shaped by partnerships between financial institutions and tech providers, driving further innovation in AML model training and privacy-preserving technologies.
Report Details
Proceed To Buy
Want a More Customized Experience?
- Request a Customized Transcript: Submit your own questions or specify changes. We’ll conduct a new call with the industry expert, covering both the original and your additional questions. You’ll receive an updated report for a small fee over the standard price.
- Request a Direct Call with the Expert: If you prefer a live conversation, we can facilitate a call between you and the expert. After the call, you’ll get the full recording, a verbatim transcript, and continued platform access to query the content and more.
68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
Request Custom Transcript
Related Transcripts
$ 1450




68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, No.52-53, Jakarta 12190, Indonesia
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093



68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071