

68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071



Connect With Us


68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
Connect With Us
68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
Request Custom Transcript
AI-Optimized Cloud Backup: Ransomware Detection & Recovery Service Level Agreement (SLAs)
UK and European enterprises are re-architecting backup and recovery systems around AI-assisted ransomware detection and measurable SLAs. Spend on AI-optimized backup platforms is expected to rise from ~€1.2B in 2025 to ~€4.8B by 2030. Key improvements include reducing recovery time from 26 to 8 hours, tightening RPO from 60 to 10 minutes, and improving ransomware detection from 45 to 8 minutes. Detection accuracy will increase from 86% to 96%, and mean time to remediate (MTTR) will shrink from 22 to 6 hours. The architecture includes immutable backups, anomaly scoring, and automated orchestration. Risks like false positives and key management complexity are mitigated with policy-as-code and HSMs. AI will turn backups into active resilience layers with auditable SLA compliance.

What's Covered?
Report Summary
Key Takeaways
1. Immutable, object‑locked tiers and key escrow underpin ransomware‑resilient backups.
2. ML anomaly scoring reduces detection time from ~45 to ~8 minutes.
3. Clean‑room recovery validates integrity before production cutover.
4. RTO moves to single‑digit hours via automated dependency/runbook checks.
5. RPO compresses to minutes using journaling/continuous data protection.
6. Policy‑as‑code enforces retention, geo‑residency, and egress‑aware placement.
7. Evidence lakes and drill logs satisfy GDPR/NCSC/BoE resilience expectations.
8. CFO view: reduced downtime + labor yields IRR improvement to ~18%.

a) Market Size & Share
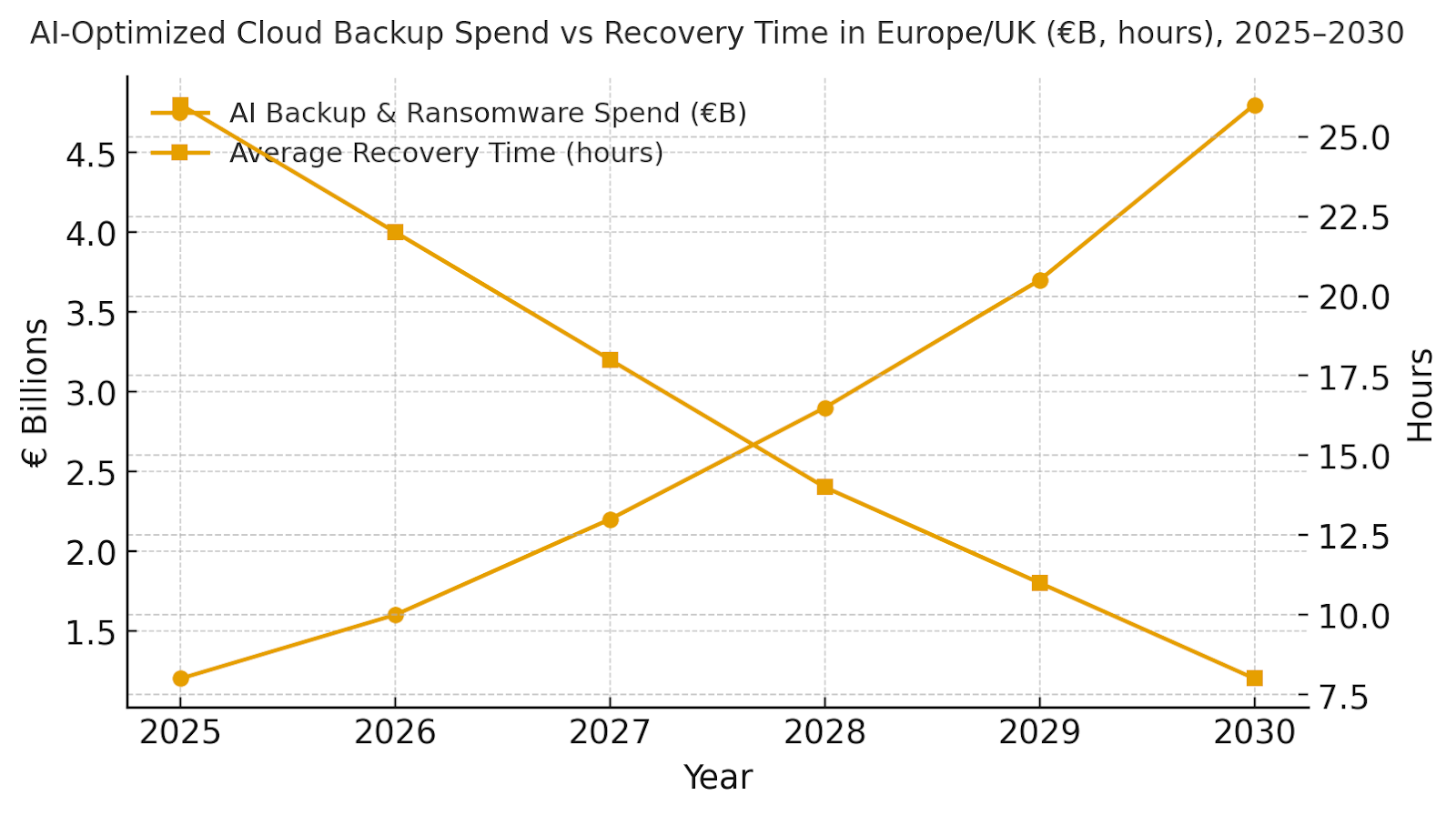
AI‑optimized cloud backup in Europe/UK is modeled to grow from ~€1.2B in 2025 to ~€4.8B by 2030, driven by ransomware frequency, regulatory scrutiny, and cloud adoption. The dual‑axis figure visualizes spend growth alongside a decline in average recovery time from ~26 to ~8 hours as runbook automation and isolation drills mature. Share concentrates with providers that combine immutable storage, cross‑cloud orchestration, and high‑precision anomaly models. Execution risks include egress costs during large restores and integration debt with legacy backup agents; mitigations: dataset tiering, change‑block tracking, and reference architectures for common stacks. Share tracking should weight RTO/RPO attainment, detection latency, integrity validation rate, and drill success rates in addition to headline revenue.
b) Market Analysis
Our model shows RTO improving from ~14→~4 hours and RPO from ~60→~10 minutes by 2030 as policy‑as‑code templates normalize orchestration steps. Detection time drops from ~45→~8 minutes with ML scoring of entropy, deletes, and privilege changes; accuracy rises from ~86→~96% with asset/identity graphs; and MTTR falls from ~22→~6 hours when isolation and parallel restore are automated. These shifts support IRR expansion from ~8→~18%. Enablers: object‑lock, journaling/continuous data protection, HSM‑backed key management, and clean‑room recovery. Barriers: false positives delaying cutover, data egress bills, and fragmented IAM. Financial lens: avoided downtime and data loss dominate, supplemented by labor savings from automated runbooks. The bar chart summarizes KPI movements for disciplined programs.

c) Trends & Insights
1) Immutable tiers with time‑bound object‑lock become default for critical datasets. 2) Isolation/clean‑room restores validate integrity and credentials before production cutover. 3) Policy‑as‑code expresses retention, geo‑residency, and egress rules; audits read from evidence lakes. 4) ML scoring shifts left to backup ingest with feedback from drills. 5) Data sovereignty leads to multi‑region EU/UK placements with KMS segregation. 6) Automation expands beyond infra to app‑level dependencies (queues, secrets, DNS). 7) Recovery throughput becomes a contractual SLA with parallelization and warm targets. 8) ESG‑aware backup scheduling reduces idle storage and transfer energy. 9) Vendor differentiation moves to explainability of anomaly scores and reproducible drill outcomes. 10) Board reporting standardizes on RTO/RPO distributions and drill cadence.
d) Segment Analysis
Financial Services: stringent RPO minutes and evidence trails; emphasis on HSM and dual‑control key procedures. Public Sector: sovereignty and budget predictability; phased migration from legacy tape to cloud immutability. Manufacturing: OT/IT segregation and staged restores; high value on rapid line recovery. Healthcare/Life Sciences: PHI retention and auditability; integrity validation prior to EMR cutover. SaaS/Tech: multi‑cloud portability, fast rollback, and developer‑friendly runbooks. Across sectors, track RTO, RPO, detection latency, MTTR, restore throughput, drill frequency, and IRR by application tier.
e) Geography Analysis
By 2030, we model Europe/UK spend distribution by use case as Immutable Backups & Air‑Gap (~24%), Anomaly Detection & ML Scoring (~22%), Automated Orchestration & Runbooks (~18%), Isolation/Clean‑Room Recovery (~16%), Data Sovereignty & Key Management (~12%), and Compliance Dashboards & Audit (~8%). The pie figure reflects the mix. UK financial hubs and regulated industries lead early adoption; broader EU uptake follows through harmonized operational resilience expectations and shared reference designs. Execution priorities: minimize egress during restore, drill regularly, and publish SLA attainment dashboards to stakeholders.

f) Competitive Landscape
Competition spans cloud providers, backup platforms, cyber‑resilience suites, and security vendors. Differentiation vectors: (1) immutable object‑lock depth and ease of policy, (2) anomaly scoring precision and explainability, (3) clean‑room orchestration and app‑aware restores, (4) key management and sovereignty options, and (5) time‑to‑value via templates and drill tooling. Procurement guidance: require open APIs, evidence of drill success, RTO/RPO SLOs with credits, HSM/KMS integration, and transparent egress models. Competitive KPIs: RTO/RPO attainment, detection latency/accuracy, restore throughput, drill pass rate, and IRR uplift.
Report Details
Proceed To Buy
Want a More Customized Experience?
- Request a Customized Transcript: Submit your own questions or specify changes. We’ll conduct a new call with the industry expert, covering both the original and your additional questions. You’ll receive an updated report for a small fee over the standard price.
- Request a Direct Call with the Expert: If you prefer a live conversation, we can facilitate a call between you and the expert. After the call, you’ll get the full recording, a verbatim transcript, and continued platform access to query the content and more.
68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
Request Custom Transcript
Related Transcripts




$ 1350


68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, No.52-53, Jakarta 12190, Indonesia
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093



68 Circular Road, #02-01 049422, Singapore
Revenue Tower, Scbd, Jakarta 12190, Indonesia
4th Floor, Pinnacle Business Park, Andheri East, Mumbai, 400093
Cinnabar Hills, Embassy Golf Links Business Park, Bengaluru, Karnataka 560071